Cómo Predecir Ingresos en Salud con Análisis Predictivo

Cómo Predecir Ingresos en Salud con Análisis Predictivo
El análisis predictivo permite a hospitales y clínicas anticipar ingresos usando datos históricos y actuales. Esto mejora la gestión financiera, reduce imprevistos y optimiza recursos. Aunque solo el 20-30% de las organizaciones sanitarias en España lo implementan, los resultados son claros: mayor precisión en las proyecciones y decisiones basadas en datos.
Claves del proceso:
- Recopilación de datos: Facturación, historiales clínicos, estadísticas de pacientes.
- Limpieza y preparación: Eliminar errores, estandarizar formatos, manejar valores ausentes.
- Modelos predictivos: Desde regresión lineal hasta redes neuronales LSTM para mayor precisión.
- Validación y seguimiento: Uso de métricas como RMSE y R² para ajustar proyecciones.
Con herramientas como Mundoctor y el cumplimiento del RGPD, el análisis predictivo se convierte en una solución práctica para prever ingresos y fortalecer la planificación financiera en el sector salud.
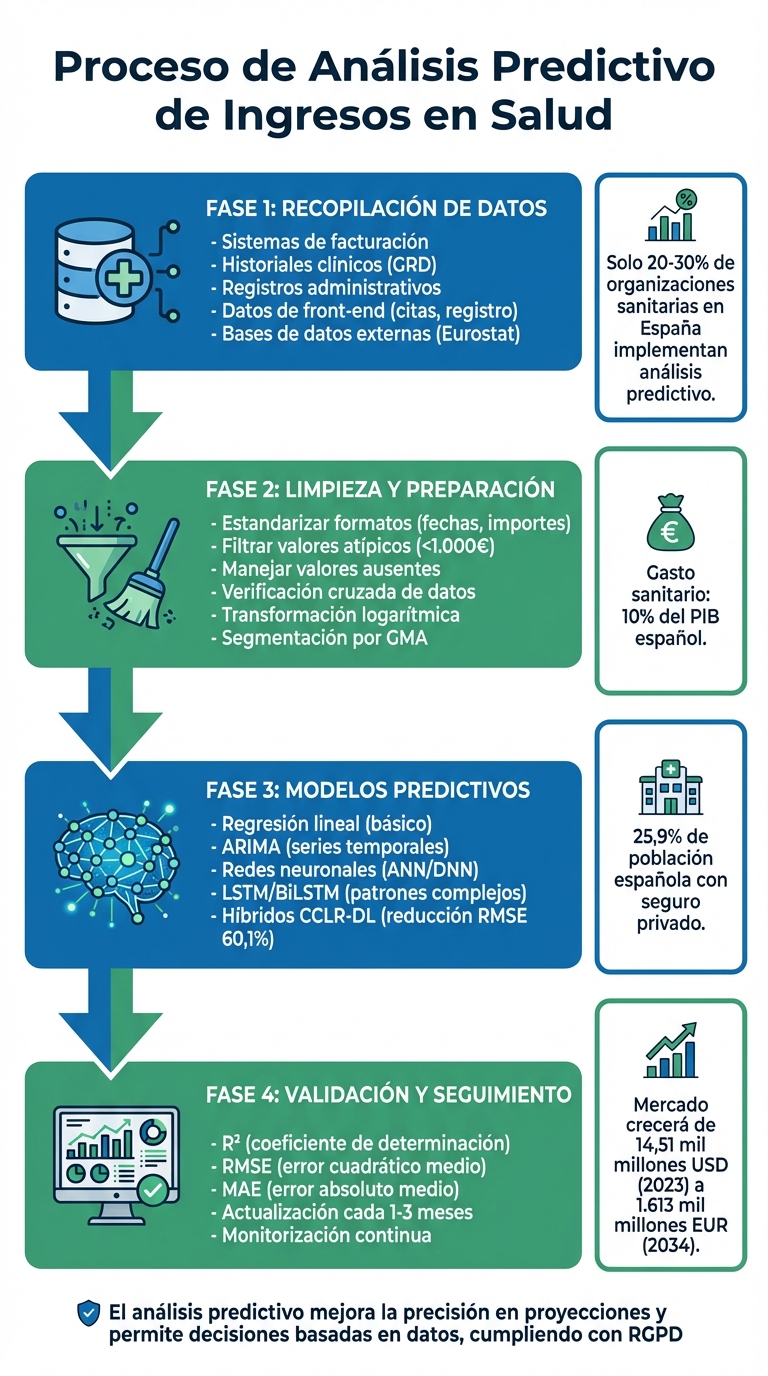
Proceso de análisis predictivo de ingresos en salud: 4 fases clave
Sistema Inteligente de Predicción de Ingresos Hospitalarios del Hospital La Fe
sbb-itb-603f8c5
Recopilación de Datos Históricos de Ingresos
Para realizar predicciones fiables, necesitas datos financieros sólidos. Sin ellos, cualquier análisis carece de fundamento. El primer paso es identificar las fuentes adecuadas y asegurarte de que la información sea precisa antes de comenzar.
Fuentes de Datos de Ingresos
Los sistemas de facturación son una fuente clave. Estos sistemas registran servicios facturados, pagos recibidos, fechas de provisión y códigos de procedimientos. Todo esto es esencial para construir una base sólida de ingresos históricos.
Por otro lado, los registros clínicos y administrativos proporcionan un contexto crucial. Elementos como los Grupos Relacionados por el Diagnóstico (GRD), las historias clínicas electrónicas y los registros personales de salud permiten vincular procedimientos médicos con sus costes asociados.
Los datos del front-end, como el registro de pacientes, la verificación de elegibilidad y la programación de citas, también son útiles. Estos datos permiten prever ingresos futuros en función de la afluencia de pacientes. Herramientas como Mundoctor centralizan esta información, combinando la gestión de citas y la facturación automatizada en un único sistema.
Las bases de datos externas y públicas son ideales para establecer comparaciones. Fuentes como Eurostat o repositorios especializados ofrecen datos históricos del sector, ayudándote a contrastar tus cifras con las tendencias generales. Además, los datos no estructurados, como notas clínicas y reportes médicos, pueden procesarse con herramientas de lenguaje natural para detectar posibles ingresos no facturados.
Garantizar la Precisión de los Datos
La calidad de los datos es clave para obtener predicciones fiables. Estandarizar los formatos es un paso esencial. Esto incluye unificar las fechas en un formato común (por ejemplo, DD-MM-AAAA) y asignar valores específicos a campos vacíos para evitar errores.
También es importante filtrar valores atípicos. Transacciones inusualmente bajas, como aquellas por debajo de 1.000 €, podrían ser errores de registro en lugar de servicios reales.
La verificación cruzada entre datos clínicos y financieros asegura que los importes facturados coincidan con los servicios prestados. Es especialmente importante identificar correctamente a los pacientes de alto coste en las previsiones. Además, la precisión en el registro inicial y la verificación de elegibilidad son fundamentales, ya que los errores en estas fases suelen causar retrasos en los pagos y pérdidas de ingresos.
"La utilidad de un modelo reside en su capacidad para representar la realidad con precisión" – García Díaz, Investigador.
Con datos fiables, se establece una base sólida para los siguientes pasos de preparación y limpieza, que se abordarán en la próxima sección.
Preparación y Limpieza de Datos para Modelos Predictivos
Una vez que se han recopilado datos históricos, es fundamental prepararlos y limpiarlos para que los modelos predictivos puedan ofrecer resultados fiables. Este paso incluye identificar errores, corregir inconsistencias y transformar los datos en un formato apto para el análisis. Sin este proceso, incluso los algoritmos más avanzados pueden generar resultados poco útiles.
Aquí te explicamos las técnicas más importantes para llevar a cabo una limpieza de datos efectiva.
Técnicas de Limpieza de Datos
El primer paso es evaluar el conjunto de datos. Esto implica buscar duplicados, columnas que no aporten información (como aquellas con valores constantes) y campos con demasiadas categorías que no sean útiles. También es clave revisar los rangos de valores para detectar datos que no tienen sentido, como ingresos negativos o importes excesivos que superen límites razonables.
Para identificar valores atípicos, utiliza herramientas gráficas como histogramas o diagramas de caja. Esto te ayudará a diferenciar entre errores y datos legítimos, como los costes elevados de ciertos tratamientos oncológicos.
El manejo de valores ausentes requiere especial atención, sobre todo en sectores como la salud. A menudo, los datos faltantes no son aleatorios. Por ejemplo, si no hay un resultado de laboratorio, puede deberse a que el médico no consideró necesario realizar esa prueba. En lugar de eliminar estos registros, una buena práctica es crear indicadores de ausencia: variables binarias que señalen si un dato está presente o no, ya que esta información puede tener valor predictivo.
"No amount of sophisticated modeling can fix garbage data." – The Clinical AI Field Guide
Cuando sea necesario imputar valores faltantes, utiliza la mediana por subgrupo en lugar de la media global. Así, si falta el coste de un tratamiento, puedes imputarlo con la mediana de costes para pacientes con un diagnóstico similar.
Otra técnica útil es la transformación logarítmica, especialmente para variables financieras con una distribución muy sesgada, como ingresos o duración de estancias hospitalarias. Esto ayuda a normalizar los datos y mejora el rendimiento de muchos algoritmos predictivos.
Por último, asegúrate de respetar las convenciones locales de formato. En España, el separador decimal es la coma (,) y el de miles es el punto (.). Por ejemplo, los importes deben representarse como 1.250,75 € en lugar de 1,250.75 €, para evitar errores en los cálculos.
Con los datos ya limpios, el siguiente paso es segmentarlos para optimizar las predicciones.
Segmentación de Datos para el Análisis
La segmentación divide los datos en grupos homogéneos, lo que mejora la precisión de los modelos. En España, los Grupos de Morbilidad Ajustada (GMA) son una herramienta eficaz para clasificar pacientes según su consumo esperado de recursos. Este sistema supera a otros métodos como los Grupos de Riesgo Clínico, con un AUC de 0,696 frente a 0,692.
En estudios internacionales, segmentar a los pacientes según patrones de uso - combinando variables sociodemográficas y cohortes de salud - ha demostrado ser útil para predecir costes médicos. Al aplicar redes neuronales LSTM junto con esta segmentación, se pueden proyectar costes con una antelación de 1 a 3 meses, validando los resultados con métricas como RMSE y R² ajustado.
Además, incluir variables inducidas como la "recencia" (tiempo desde la última consulta) y la "frecuencia" de uso de servicios puede ser muy útil. Estas variables ayudan a distinguir a pacientes activos de inactivos, lo que es un fuerte indicador de ingresos a corto plazo. En el contexto español, también es relevante segmentar por fuente de financiación: público (74%) y privado (26%). Dentro del sector privado, se pueden diferenciar el gasto de bolsillo, los seguros privados y el mutualismo administrativo.
Con los datos ya transformados y segmentados, es posible identificar grupos más homogéneos, lo que mejora la precisión de los modelos predictivos. Este enfoque combinado - segmentar primero y predecir después - suele generar resultados más fiables que aplicar un único modelo a toda la población.
Elección y Aplicación de Modelos Predictivos
Una vez que los datos están listos y segmentados, el siguiente paso es seleccionar el modelo predictivo adecuado. La elección dependerá de factores como la complejidad de los datos, los recursos disponibles y el equilibrio entre precisión y facilidad de interpretación.
Los modelos estadísticos tradicionales, como la regresión lineal o ARIMA, son herramientas claras y sencillas que permiten identificar qué variables afectan los ingresos. Sin embargo, su capacidad se limita cuando los datos son complejos o presentan relaciones no lineales. Por otro lado, los modelos de aprendizaje profundo, como las redes neuronales LSTM, ofrecen un nivel de precisión superior, aunque su funcionamiento interno es más difícil de interpretar, lo que a menudo se describe como una "caja negra".
"Mientras que los métodos estadísticos proporcionan interpretabilidad, a menudo carecen de poder predictivo. Por el contrario, los modelos de aprendizaje profundo logran alta precisión pero actúan como 'cajas negras'." – Computer Methods and Programs in Biomedicine
Los enfoques híbridos, como el marco CCLR-DL, combinan lo mejor de ambos mundos: utilizan métodos estadísticos para seleccionar variables importantes y redes neuronales para mejorar la precisión. Este tipo de modelo puede reducir el error cuadrático medio (RMSE) hasta en un 60,1 %. Para predicciones a corto plazo (de 1 a 3 meses), las redes BiLSTM destacan al capturar patrones temporales complejos en ambas direcciones.
Un ejemplo concreto lo encontramos en el sistema implementado por Keralty en Colombia entre 2017 y 2021. En este proyecto, se analizaron más de 160 millones de registros de facturación utilizando una combinación de clustering k-means y redes LSTM. Variables como la edad, las comorbilidades y el tiempo desde la última consulta se incluyeron en el análisis. Este enfoque mejoró la precisión de las proyecciones, lo cual fue validado mediante métricas como RMSE y R² ajustado.
Visión General de los Modelos Predictivos Comunes
Con los datos preparados, es importante entender cómo cada enfoque predictivo se adapta a las necesidades del análisis. Por ejemplo, la regresión lineal es una opción básica que establece relaciones directas entre variables, como el número de consultas y la facturación mensual. Aunque fácil de interpretar, este modelo asume relaciones lineales constantes, algo poco frecuente en el ámbito sanitario.
Los modelos ARIMA son útiles para series temporales con tendencias y estacionalidades claras, como aumentos en temporada de gripe o disminuciones en otras épocas. Sin embargo, no capturan interacciones complejas entre múltiples variables.
Las redes neuronales artificiales (ANN) y sus variantes avanzadas, como las redes neuronales profundas (DNN), son capaces de analizar datos multidimensionales y detectar patrones no lineales. Estas son especialmente útiles para predecir pagos promedio en Grupos Relacionados por el Diagnóstico (GRD). Las redes LSTM van un paso más allá al retener información a largo plazo, lo que las hace ideales para datos sanitarios donde el historial del paciente tiene un impacto directo en los ingresos futuros.
"Las LSTM son una extensión de las RNN anteriores que son capaces de retener una memoria a largo plazo y usarla para aprender patrones en secuencias más largas de datos fuente." – Sandoval Serrano et al.
Por último, aunque el clustering k-means no es un modelo predictivo en sí, agrupa pacientes con características similares. Esto permite aplicar modelos específicos a cada grupo, logrando proyecciones más precisas que con un único modelo general.
Comparación de Algoritmos para la Previsión de Ingresos
A continuación, se presenta una tabla comparativa que resume las características principales de los modelos más utilizados:
| Tipo de Modelo | Ventajas | Desventajas | Requisitos de Datos |
|---|---|---|---|
| Estadístico (Regresión/ARIMA) | Fácil de interpretar e implementar | Limitado para datos complejos y no lineales | Series temporales históricas |
| Redes Neuronales (ANN/DNN) | Manejan datos complejos y multidimensionales | Funcionan como "cajas negras" y requieren recursos computacionales elevados | Grandes volúmenes de datos |
| LSTM / BiLSTM | Capturan patrones a largo plazo y dependencias temporales | Entrenamiento complejo; necesitan secuencias históricas extensas | Datos secuenciales o series temporales |
| Híbrido (CCLR-DL) | Combina precisión con capacidad de interpretación; reduce RMSE hasta un 60,1 % | Diseño e implementación más complejos | Datos multivariantes de alta dimensión |
Si tu organización cuenta con datos históricos limitados o necesitas justificar las predicciones ante la dirección, los modelos estadísticos son una buena opción inicial. En cambio, si dispones de registros detallados y buscas optimizar la precisión, las redes LSTM o los enfoques híbridos son más adecuados. Siempre es importante validar los resultados con métricas como RMSE y R² ajustado antes de tomar decisiones basadas en las proyecciones.
Implementación de Modelos Predictivos con Plataformas de Análisis
Una vez que los datos han sido limpiados y segmentados, el siguiente paso es integrar el modelo predictivo en plataformas de análisis que conviertan esa información en proyecciones útiles. Tras seleccionar el modelo adecuado, es fundamental conectarlo con sistemas que generen informes y permitan visualizar las proyecciones de ingresos. Además, es clave vincular los datos clínicos con los sistemas de gestión financiera para obtener una visión completa de los costes por paciente y las tendencias de facturación.
Uso de Herramientas de Análisis para la Implementación
Para que la implementación sea efectiva, es necesario utilizar una plataforma que combine datos multivariantes, como GRD, comorbilidades, EBITDA y facturación. Estas herramientas deben ser compatibles con algoritmos avanzados, como redes LSTM para series temporales, y permitir la segmentación de la población mediante técnicas de clustering antes de aplicar los modelos predictivos.
Un ejemplo destacado es el proyecto de la red hospitalaria Vithas entre 2019 y 2021, donde se implementaron Mapas Auto-Organizados (SOM) en 14 hospitales. Este proyecto analizó 47 indicadores estandarizados para identificar relaciones no lineales entre la actividad hospitalaria y las métricas financieras. Los resultados revelaron que las ventas y el EBITDA estaban estrechamente relacionados con la actividad programada a corto plazo, mientras que factores como la satisfacción del paciente y la accesibilidad influían en los resultados financieros a mediano plazo (3 a 6 meses).
Las plataformas actuales también ofrecen herramientas que automatizan el ciclo de vida completo del modelo, abarcando desde la preparación de datos y el entrenamiento hasta el despliegue en entornos de prueba o producción. Tecnologías como flujos visuales AutoAI y cuadernos en Python, R o Scala aportan flexibilidad para realizar análisis personalizados.
Para los profesionales sanitarios que necesitan una solución integral, plataformas como Mundoctor destacan por facilitar la generación de informes financieros y la exportación de datos necesarios para alimentar modelos predictivos. Además, sus funciones de facturación automatizada y análisis estructurado de datos aseguran una gestión eficiente de la información del paciente, lo que es clave para obtener proyecciones precisas.
Una vez que la plataforma de análisis está operativa, es imprescindible garantizar el cumplimiento normativo, especialmente en lo referente al RGPD.
Garantizar el Cumplimiento del RGPD
La implementación de modelos predictivos en el ámbito sanitario debe cumplir estrictamente con el Reglamento General de Protección de Datos (RGPD). Esto incluye adherirse a principios como legalidad, equidad, transparencia, minimización de datos e integridad, establecidos en los artículos 5 a 9.
"Los datos personales que hayan sido objeto de seudonimización, que podrían atribuirse a una persona física mediante la utilización de información adicional, deben considerarse información sobre una persona física identificable." – RGPD de la Unión Europea
La seudonimización es una técnica clave en este contexto. Los datos sensibles de los pacientes deben ser tratados de forma seudonimizada antes de transferirlos a las plataformas de análisis, reduciendo así el riesgo de identificación individual.
Un caso práctico es el Sistema Público de Salud de Andalucía (SSPA), que entre 2021 y 2025 implementó la plataforma PAGEM, gestionada por la Fundación Progreso y Salud. Este proyecto integró un lago de datos médicos de 15,8 millones de pacientes, procesando 874 millones de diagnósticos y 7.000 millones de imágenes médicas. Los datos seudonimizados permanecieron dentro de la red corporativa, garantizando la seguridad y evitando accesos no autorizados.
Las plataformas deben incorporar herramientas para rastrear la trazabilidad de los datos, aplicar flujos de enmascaramiento para información sensible y monitorizar posibles sesgos. Además, es crucial realizar una Evaluación de Impacto en la Protección de Datos (EIPD), que describa el ciclo de vida de la información, identifique riesgos y defina medidas de mitigación. Este proceso generalmente incluye pasos como: aprobación del estudio, extracción y seudonimización de datos, transferencia segura a la herramienta de análisis, análisis y destrucción final de los datos.
Mundoctor aborda el cumplimiento del RGPD de manera integral, ofreciendo funcionalidades como consentimiento digital, copias de seguridad automáticas y gestión segura de la información del paciente. Esto permite a los profesionales sanitarios realizar análisis predictivos sin comprometer la privacidad ni la seguridad de los datos de sus pacientes.
Validación y Monitorización de Predicciones
Una vez que el modelo está en marcha, es fundamental asegurarse de que las proyecciones de ingresos reflejen la realidad. Tomar decisiones basadas en datos incorrectos podría poner en peligro la estabilidad financiera del centro sanitario. Para evitarlo, divide los datos históricos: utiliza el 80% para entrenar el modelo y el 20% para pruebas. Esto ayuda a prevenir el sobreajuste y garantiza que el modelo pueda generalizarse correctamente.
Métricas de Validación para Modelos Predictivos
El Coeficiente de Determinación (R-cuadrado) mide qué porcentaje de la variabilidad en los ingresos explica el modelo. Un valor cercano a 1,0 indica un modelo altamente explicativo. Por ejemplo, en diciembre de 2025, Katherin Jiménez y María Fernanda Rosero validaron un modelo de costes médicos basado en 1.338 observaciones, logrando un R-cuadrado ajustado de 0,7578. Esto significaba que el modelo explicaba el 75,8% de la varianza en los cargos médicos.
Para evaluar el margen de error en términos monetarios, se utilizan dos métricas clave: Error Absoluto Medio (MAE) y Raíz del Error Cuadrático Medio (RMSE). El MAE calcula la diferencia promedio entre los valores reales y los predichos, sin dar mayor peso a los errores grandes. Por otro lado, el RMSE penaliza más los errores significativos. En el estudio mencionado, el RMSE alcanzó los 6.290,48 €, un dato relevante para planificar reservas presupuestarias. Si el centro sanitario tiene poca tolerancia a grandes desviaciones financieras, el RMSE es más útil. Sin embargo, si hay valores atípicos que podrían distorsionar los resultados, el MAE ofrece una medida más estable.
"La utilidad de un modelo reside en su capacidad para representar la realidad con precisión... la falta de validación de estos modelos puede generar sesgos y errores que afectan la calidad del servicio." – María Fernanda Rosero, Investigadora
Además de estas métricas, es importante analizar los residuos, es decir, las diferencias entre los valores reales y los predichos. Representar gráficamente estos residuos puede revelar patrones no aleatorios, como la heterocedasticidad. Si los residuos forman una figura similar a un "embudo", podría ser necesario ajustar el modelo con transformaciones logarítmicas o técnicas no lineales para reflejar mejor factores como el aumento exponencial de costes con la edad o ciertos riesgos de salud.
Seguimiento de Ingresos Reales frente a Predichos
El monitoreo constante de los costes hospitalarios es clave. Actualiza las proyecciones cada 1 a 3 meses para identificar y corregir desviaciones antes de que se conviertan en problemas graves. Esto permite detectar discrepancias significativas a tiempo y ajustar el modelo predictivo de manera oportuna.
Un enfoque eficaz es implementar un ciclo de mejora continua basado en los pasos: Monitorizar, Analizar, Planificar y Ejecutar. Este proceso incluye el seguimiento de indicadores clave como el número de reclamaciones rechazadas, los patrones de pago de los pacientes y posibles fugas de ingresos. Estos datos deben compararse constantemente con las predicciones del modelo. Si se detectan patrones sistemáticos en los residuos, puede ser necesario eliminar variables irrelevantes o aplicar técnicas de segmentación poblacional, como el clustering, para mejorar la precisión del modelo.
Con estos ajustes y un seguimiento constante, se pueden perfeccionar las proyecciones de ingresos, lo que prepara el terreno para optimizaciones futuras, que se abordarán en la siguiente sección.
Mejora de las Previsiones de Ingresos con Análisis Financiero Avanzado
Una vez validado el modelo, el siguiente paso es ajustarlo para reflejar los constantes cambios del mercado sanitario. Este refinamiento es clave para llevar las predicciones de ingresos a un nivel más preciso. En un sector donde el gasto sanitario y la importancia del sector privado no dejan de crecer, los modelos sin actualizaciones pierden efectividad rápidamente. Incorporar tendencias macroeconómicas y actualizar algoritmos de forma periódica permite prever mejor los flujos de ingresos futuros. Aquí exploraremos cómo adaptar su modelo a estas dinámicas.
Incorporación de Tendencias de Mercado
El entorno económico y demográfico tiene un impacto directo en los ingresos de los centros sanitarios. En España, el 25,9% de la población cuenta con seguro privado de salud, lo que demuestra la importancia de reflejar esta tendencia en los modelos predictivos. Además, factores como el envejecimiento de la población y el aumento de enfermedades crónicas están cambiando los patrones de consumo de servicios médicos. Por ejemplo, en 2018, el 14% de los ingresos hospitalarios fueron reingresos, de los cuales un 20% estuvieron relacionados con enfermedades crónicas como la diabetes y la insuficiencia cardíaca.
Para captar estas dinámicas, es útil segmentar la población antes de realizar predicciones. Un caso interesante es el de la red hospitalaria Vithas en España, que en noviembre de 2025 utilizó Mapas Auto-Organizados (SOM) para analizar 47 indicadores en 14 hospitales. Este estudio, liderado por David Baulenas-Parellada, mostró que, mientras la actividad programada tenía un impacto inmediato en las ventas y el EBITDA, indicadores como la satisfacción del paciente y la accesibilidad predecían resultados financieros a 3 y 6 meses.
Además, incluir variables socioeconómicas específicas puede mejorar significativamente los modelos. Entre 2013 y 2014, el Servicio Canario de Salud realizó un estudio en 18 zonas de salud (con 385.049 usuarios) y logró aumentar la precisión de las predicciones de ingresos hospitalarios a un AUC de 0,708. Esto se consiguió añadiendo escalas funcionales como Barthel y Pfeiffer, junto con el número de grupos terapéuticos prescritos.
Con estas tendencias identificadas, actualizar y refinar los modelos resulta esencial para mantener la precisión en las proyecciones.
Actualización de Modelos para Mejores Resultados
Los modelos predictivos necesitan ser dinámicos. Refinarlos constantemente con datos recientes es crucial para mantener su relevancia, sobre todo frente a cambios imprevistos como pandemias o el auge de la telemedicina. Incorporar datos actualizados permite ajustar las proyecciones antes de que las desviaciones se conviertan en problemas financieros.
Un ejemplo destacado es el de Keralty en Colombia, que implementó un enfoque en dos fases: segmentación mediante clustering y proyección con redes LSTM. Este enfoque mejoró notablemente la fiabilidad de las predicciones. Este caso demuestra que segmentar la población antes de aplicar algoritmos de series temporales mejora las estimaciones.
Otra estrategia eficaz es incluir indicadores causales utilizando herramientas estadísticas como la causalidad de Granger. Además, aplicar marcos híbridos como CCLR-DL puede reducir el error cuadrático medio (RMSE) hasta en un 60,1%.
"Comprender cómo y por qué aumentan los factores de coste puede proporcionar información sobre los factores de riesgo y los posibles puntos de partida para definir medidas y estrategias preventivas." – MDPI, Algorithms
Estas prácticas no solo mejoran la precisión de las previsiones, sino que también preparan los modelos para ofrecer proyecciones más alineadas con la realidad del mercado sanitario en España.
Conclusión y Puntos Clave
Beneficios del Análisis Predictivo para el Sector Salud
El análisis predictivo está cambiando la forma en que se gestiona la salud financiera. En lugar de reaccionar ante problemas ya ocurridos, esta metodología permite anticipar rechazos de reclamaciones, detectar fugas de ingresos y optimizar recursos antes de que impacten negativamente en los resultados. Este enfoque es especialmente relevante en España, donde el gasto sanitario alcanza el 10% del PIB nacional.
Los resultados hablan por sí mismos. Por ejemplo, en 2024, Corewell Health evitó 200 reingresos, ahorrando 5 millones de dólares, mientras que NYU Langone Health logró un 80% de precisión en la identificación de pacientes en riesgo con su algoritmo NYUTron. Estos casos ilustran cómo una mayor precisión en las predicciones se traduce en beneficios económicos claros.
"Adoptar estrategias de análisis predictivo más proactivas en lugar de solo el enfoque reactivo tiene el potencial de aumentar enormemente la captura de ingresos, disminuir las tasas de denegación y aumentar la eficiencia operativa." – Ritesh Chaturvedi y Dr. Saloni Sharma
Además del ahorro directo, estas herramientas mejoran la gestión integral del ciclo de ingresos. Desde prever la demanda de recursos médicos y ajustar el personal según necesidades reales, hasta detectar patrones sospechosos en transacciones que podrían indicar fraude. Incluso los presupuestos pueden elaborarse con mayor precisión al basarse en el estado de salud real de la población, utilizando métodos como los Grupos de Morbilidad Ajustados, que superan los enfoques tradicionales basados únicamente en datos demográficos.
Este enfoque no solo optimiza procesos, sino que también redefine la estrategia financiera en el sector sanitario.
Próximos Pasos para Profesionales Sanitarios
Aunque el potencial del análisis predictivo es evidente, su adopción aún es limitada. Actualmente, entre el 60% y el 70% de las organizaciones sanitarias dependen de análisis básicos, mientras que solo el 20%-30% han incorporado herramientas predictivas. Sin embargo, el mercado está en expansión: se estima que crecerá de 14,51 mil millones de dólares en 2023 a 17,99 mil millones en 2024, alcanzando aproximadamente 1.613 mil millones de euros para 2034.
Para comenzar, implementa un ciclo continuo de "Monitorizar-Analizar-Planificar-Ejecutar". Este enfoque permite refinar procesos en tiempo real utilizando datos actualizados. Prioriza áreas de impacto inmediato, como la predicción de rechazos de reclamaciones o la probabilidad de pago de pacientes. Herramientas como Mundoctor facilitan este cambio al combinar análisis predictivos con la gestión diaria de pacientes, automatizar la facturación y garantizar el cumplimiento del RGPD, eliminando la necesidad de infraestructuras complicadas.
El éxito de esta transición depende de contar con tecnología adecuada y profesionales capacitados en salud y analítica. Comienza por limpiar y organizar tus datos, segmenta tu población antes de aplicar modelos predictivos y asegúrate de actualizar regularmente los algoritmos para mantener la precisión y relevancia de las proyecciones. Este enfoque no solo mejora la toma de decisiones, sino que también prepara a las organizaciones para un futuro más eficiente y orientado a resultados.
FAQs
¿Qué datos mínimos necesito para predecir ingresos?
Para anticipar ingresos en el ámbito de la salud, es fundamental contar con ciertos datos clave. Entre ellos se encuentran las variables demográficas, como la edad y el sexo, que ofrecen una base inicial para entender al paciente. Además, resulta crucial incluir antecedentes clínicos y datos obtenidos durante el triaje o la evaluación de prioridad de atención.
Otro aspecto importante es recopilar información sobre el historial médico del paciente y los recursos utilizados durante su atención. Estos elementos permiten identificar patrones y características esenciales que ayudan a construir modelos predictivos más precisos, ofreciendo una visión más completa del proceso de atención médica y las necesidades del paciente.
¿Qué modelo conviene si tengo pocos datos históricos?
Cuando dispones de pocos datos históricos, una buena opción es recurrir a modelos de regresión lineal o a algoritmos diseñados para trabajar con volúmenes de datos limitados. Estos métodos suelen emplearse en investigaciones sobre predicción en el ámbito de la salud con conjuntos de datos reducidos y han demostrado ofrecer resultados efectivos en contextos parecidos.
¿Cómo cumplo el RGPD al usar datos de pacientes en predicciones?
Cuando trabajas con datos de pacientes para realizar predicciones, es fundamental proteger su privacidad y asegurarte de cumplir con el Reglamento General de Protección de Datos (RGPD). Aquí tienes algunas prácticas clave para lograrlo:
- Anonimización o pseudonimización: Antes de procesar cualquier dato, elimina o reemplaza cualquier información que pueda identificar directamente a los pacientes. Esto reduce significativamente el riesgo de que alguien pueda asociar los datos con una persona específica.
- Consentimiento explícito: Asegúrate de obtener el consentimiento claro y directo de los pacientes antes de usar sus datos. Este consentimiento debe detallar cómo se utilizarán los datos y para qué fines.
- Uso legítimo y específico: Los datos deben emplearse únicamente para objetivos claramente definidos y legítimos. Evita cualquier uso que no se haya especificado previamente.
- Controles de acceso seguros: Limita el acceso a los datos únicamente a personas autorizadas. Implementa medidas como contraseñas robustas, autenticación de dos factores y registros de acceso para garantizar la seguridad.
Además, es crucial minimizar los riesgos de reidentificación. Esto implica evaluar regularmente los métodos de anonimización y asegurarte de que sean efectivos. Si trabajas con terceros para procesar estos datos, verifica que cumplan estrictamente con las normativas del RGPD. Esto incluye establecer acuerdos claros y realizar auditorías periódicas para garantizar que se respeten las medidas de protección.
Proteger los datos de los pacientes no solo es una obligación legal, sino también una responsabilidad ética.