Cómo detectar sesgos en algoritmos médicos

Cómo detectar sesgos en algoritmos médicos
Detectar sesgos en algoritmos médicos es fundamental para evitar desigualdades en la atención sanitaria. Los sesgos suelen originarse en los datos de entrenamiento, el diseño del modelo o su implementación. Estos errores pueden llevar a diagnósticos incorrectos o tratamientos desiguales para ciertos grupos.
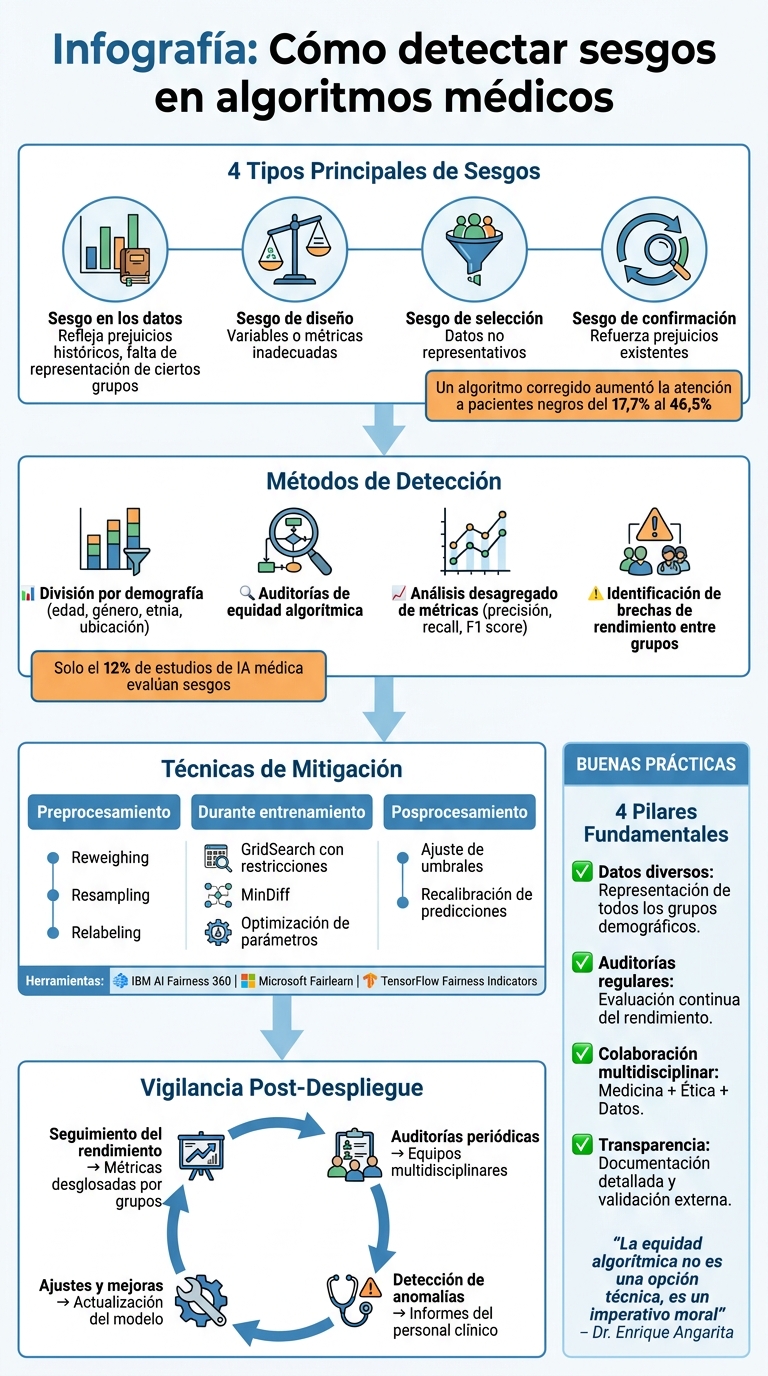
Principales tipos de sesgos:
- Sesgo en los datos: Refleja prejuicios históricos, como la falta de representación de ciertos grupos.
- Sesgo de diseño: Surge al elegir variables o métricas inadecuadas.
- Sesgo de selección: Ocurre al recopilar datos no representativos.
- Sesgo de confirmación: Refuerza prejuicios existentes.
Ejemplo real:
Un estudio de 2019 mostró cómo un algoritmo subestimaba la atención para pacientes negros al usar el "coste sanitario" como indicador en lugar de la "necesidad clínica". Corregir este sesgo aumentó la atención del 17,7% al 46,5%.
Soluciones prácticas:
- Datos diversos: Asegurar que los conjuntos de datos incluyan a todos los grupos demográficos.
- Auditorías regulares: Evaluar el rendimiento del algoritmo en diferentes subgrupos.
- Técnicas estadísticas: Usar métodos como reequilibrio de datos o ajustes en el entrenamiento.
- Colaboración multidisciplinar: Incluir expertos en medicina, ética y datos.
Detectar y corregir estos sesgos no solo mejora los resultados médicos, sino que también promueve la igualdad en el acceso a la salud.
Guía completa para detectar y corregir sesgos en algoritmos médicos
IA en sanidad: cómo se generan los sesgos y qué podemos hacer para reducirlos
sbb-itb-603f8c5
De dónde proviene el sesgo en los datos de entrenamiento
Los datos de entrenamiento son la base de los algoritmos médicos, pero también representan una de las principales fuentes de sesgo. Si estos datos arrastran desigualdades históricas, exclusiones sistemáticas o errores en su recopilación, los algoritmos terminan aprendiendo y replicando esas mismas distorsiones.
Según el Dr. Enrique Angarita: "Los sistemas de IA no son neutros. Reproducen el mundo en que fueron creados, con sus luces y sombras".
Por ello, es crucial examinar cómo se introducen los sesgos desde la preparación de los datos. A continuación, se presentan ejemplos concretos y sus consecuencias en el desempeño de los algoritmos.
Datos desequilibrados y grupos ausentes
Un conjunto de datos que no representa adecuadamente a toda la población objetivo compromete el rendimiento del algoritmo. Por ejemplo, si los datos de entrenamiento se centran principalmente en hombres de mediana edad europeos, las predicciones serán menos fiables para mujeres, personas mayores o minorías étnicas.
Un estudio del Instituto Nacional de Estándares y Tecnología de Estados Unidos (NIST) reveló que los sistemas de reconocimiento facial son mucho menos precisos al identificar a personas de ascendencia africana o asiática. En el ámbito de la salud cardiovascular, se ha observado que los algoritmos tienen un desempeño inferior en mujeres, debido a la falta de datos femeninos representativos.
Las métricas globales pueden ocultar estas fallas. Un modelo puede mostrar un alto nivel de precisión general, pero fallar de forma considerable en ciertos grupos, enmascarando así las disparidades. En el caso de la gestión de citas médicas, estas deficiencias pueden llevar a errores en la programación de pacientes, lo que subraya la importancia de mejorar la calidad y la diversidad de los datos de entrenamiento.
Estos problemas también ponen de manifiesto la necesidad de analizar cuidadosamente el uso de variables proxy, un tema que se aborda en la siguiente sección.
Problemas con las variables proxy
Las variables proxy son indicadores sustitutos usados cuando no es posible medir directamente el atributo de interés. Un ejemplo destacado es un estudio publicado en Science en octubre de 2019, que examinó un algoritmo que usaba el "coste sanitario total" como proxy para predecir la necesidad de cuidados intensivos. El problema radicaba en que, históricamente, los pacientes negros habían tenido menos acceso a servicios de salud y, por ende, generaban menores costes. El algoritmo interpretó erróneamente que estaban "más sanos" que los pacientes blancos con las mismas condiciones clínicas.
Este uso de variables proxy reflejaba desigualdades estructurales en el acceso a la atención médica, lo que resultó en una discriminación sistemática. Los pacientes negros, en muchos casos, debían estar en estados más avanzados de enfermedad para recibir el mismo nivel de atención que otros grupos.
Limitaciones de las métricas estándar
La precisión global es una métrica común para evaluar algoritmos, pero no siempre detecta sesgos. Un modelo puede tener un alto nivel de precisión general, pero fallar en subgrupos específicos, especialmente si estos representan una pequeña proporción del conjunto de datos.
Métricas alternativas, como el F1 score o el análisis desagregado por subgrupos demográficos, son esenciales para identificar estas desigualdades ocultas.
El Dr. Enrique Angarita alerta: "Si un sistema de IA se entrena principalmente con datos de un grupo demográfico específico, puede no ser capaz de diagnosticar o tratar adecuadamente a pacientes de otros grupos".
Esto resalta la importancia de evaluar el rendimiento del algoritmo de forma desagregada, analizando su eficacia en cada segmento poblacional. Así, se evita que las métricas globales oculten discriminaciones y se promueve un análisis más detallado y justo.
Evaluación del rendimiento del algoritmo en diferentes grupos
Cuando se trata de identificar sesgos en los datos, asegurar la equidad del algoritmo en distintos grupos demográficos es clave. No basta con obtener una alta métrica global; el rendimiento debe ser consistente en todos los segmentos poblacionales.
Según el Dr. Enrique Angarita: "Establecer métricas claras y desglosar los datos es esencial para un diagnóstico preciso del sesgo".
Para lograrlo, es necesario dividir los datos estratégicamente y aplicar métricas específicas que puedan revelar posibles disparidades. A continuación, repasamos algunos enfoques prácticos para esta evaluación.
División de datos por demografía
Una de las primeras acciones para detectar sesgos es segmentar los datos en función de variables como edad, género, origen étnico, ubicación (urbana o rural) y nivel socioeconómico. Este desglose permite analizar si el rendimiento del algoritmo varía entre diferentes grupos.
Las auditorías de equidad algorítmica son una herramienta útil para este propósito. Estas pruebas evalúan cómo funciona el sistema en distintos subgrupos antes de su implementación. Por ejemplo, en un sistema diseñado para predecir la demanda de citas médicas, es crucial comprobar que el algoritmo sea igualmente preciso al prever las necesidades de pacientes mayores y de adultos jóvenes, o que funcione de manera uniforme tanto en áreas rurales como en zonas metropolitanas.
Identificación de brechas de rendimiento
Tras segmentar los datos, el siguiente paso es aplicar métricas como precisión y recall a cada grupo y realizar pruebas de robustez para analizar cómo el algoritmo responde a variaciones en los datos de entrada o escenarios distintos. Este enfoque desagregado facilita la detección de diferencias significativas en el rendimiento entre segmentos.
Por ejemplo, si se encuentra que la precisión del algoritmo es notablemente mayor en hombres que en mujeres, esto señalaría una brecha de rendimiento que debe abordarse. En el caso de algoritmos cardiovasculares, se ha observado que su efectividad disminuye en mujeres cuando los datos de entrenamiento no incluyen una representación femenina adecuada.
Este análisis detallado es indispensable para identificar grupos que puedan estar siendo tratados de manera desigual y medir la magnitud de estas disparidades. Así, se pueden implementar ajustes antes de que el sistema sea utilizado en contextos críticos como el clínico.
Métodos para detectar y reducir sesgos
Una vez identificadas las brechas de rendimiento, se pueden aplicar diversas estrategias para detectar y reducir los sesgos en los modelos. Estas abarcan desde auditorías exhaustivas hasta ajustes técnicos en los algoritmos.
La auditoría algorítmica examina cada etapa del desarrollo y operación para identificar posibles sesgos, tanto en los datos de entrenamiento como en la interpretación de los resultados. Por otro lado, los protocolos de curación de datos se encargan de eliminar registros incompletos y corregir inconsistencias, asegurando que la información sea fiable y precisa.
Según el Dr. Enrique Angarita: "La responsabilidad de los desarrolladores de IA debe ser mantener la transparencia y calibrar sus algoritmos de manera que minimicen el riesgo de error y mejoren los resultados en los pacientes".
La colaboración entre disciplinas es otro pilar clave. Profesionales de tecnología, medicina y ciencias sociales trabajan juntos para aportar diferentes perspectivas, lo que resulta esencial para identificar sesgos que un equipo más homogéneo podría no detectar. Este enfoque se aplica en sistemas como los que gestionan citas médicas, favoreciendo un acceso más equitativo para todos los usuarios.
Métodos estadísticos para la detección de sesgos
Existen técnicas estadísticas específicas que ayudan a identificar y abordar sesgos en distintas etapas del desarrollo del modelo. Entre las más utilizadas están las de preprocesamiento, como Reweighing, Resampling y Relabeling, que equilibran los datos antes del entrenamiento.
Durante el entrenamiento, las técnicas de procesamiento interno ajustan el algoritmo para incluir la equidad como uno de sus objetivos. Por ejemplo, herramientas como GridSearch con restricciones de equidad permiten optimizar el modelo teniendo en cuenta tanto su precisión como su justicia. También se emplean métodos como MinDiff, que penalizan las diferencias en las distribuciones de predicción entre distintos grupos, ayudando a equilibrar los errores.
En la etapa de posprocesamiento, se pueden ajustar los umbrales de decisión o recalibrar las predicciones para garantizar resultados más justos. Herramientas como IBM AI Fairness 360 (aif360) y Microsoft Fairlearn son particularmente útiles para medir y mitigar sesgos de forma sistemática.
Validación cruzada y optimización de parámetros
Las pruebas de robustez son esenciales para evaluar cómo se comporta un algoritmo en diferentes escenarios, ayudando a identificar posibles sesgos que solo aparecen bajo ciertas condiciones.
El Dr. Enrique Angarita destaca: "Al someter a los algoritmos a diferentes escenarios, es posible detectar si mantienen su eficacia o si exhiben un comportamiento sesgado en ciertas condiciones, lo que pone de manifiesto la necesidad de ajustar sus parámetros para garantizar la equidad en los resultados".
La validación cruzada, por su parte, evalúa el rendimiento del modelo en diferentes subconjuntos de datos, asegurando que funcione de manera consistente entre distintas poblaciones. Esto, combinado con técnicas como grid search para optimizar parámetros, permite encontrar configuraciones que minimicen tanto los errores como las disparidades entre grupos. Sin embargo, es importante tener en cuenta que, incluso con parámetros ajustados, un modelo entrenado con datos homogéneos difícilmente será eficaz para poblaciones diversas.
Monitorización y auditoría tras el despliegue
Detectar sesgos antes del despliegue es fundamental, pero una vez que el sistema opera en escenarios reales, pueden surgir nuevos sesgos. Los datos, las poblaciones y las condiciones clínicas cambian con el tiempo, lo que hace imprescindible mantener una vigilancia constante.
Como explica el Dr. Enrique Angarita: "La vigilancia constante en este campo ayudará a detectar anomalías en los resultados clínicos atribuidas a sesgos".
La Organización Mundial de la Salud destaca la importancia de "promover tecnologías receptivas y sostenibles que puedan supervisarse, actualizarse y adaptarse con el tiempo". En este sentido, el lanzamiento del algoritmo no es el final, sino el inicio de una etapa de supervisión activa para garantizar resultados precisos y justos. A continuación, se presentan estrategias prácticas para monitorizar y auditar algoritmos tras su implementación.
Seguimiento del rendimiento a lo largo del tiempo
Tras detectar sesgos durante el entrenamiento, el siguiente paso es monitorear el rendimiento del algoritmo en situaciones reales. Esto requiere un sistema de seguimiento continuo que evalúe cómo se comporta el modelo en entornos operativos. Es crucial analizar métricas como precisión, tasa de error o sensibilidad, desglosadas por grupos demográficos (edad, género, etnia, nivel socioeconómico), ya que los promedios generales pueden ocultar desigualdades importantes.
Un ejemplo relevante es un estudio de octubre de 2019, que mostró que ajustar un algoritmo incrementó la elegibilidad de pacientes negros para programas de atención adicional del 17,7% al 46,5%, al corregir el uso de costes sanitarios como indicador de necesidad médica.
También es necesario identificar si ciertos grupos quedan excluidos del flujo de datos del algoritmo, un problema conocido como sesgo de desgaste (attrition bias), que podría alterar los resultados a largo plazo. Además, realizar pruebas de robustez periódicas con datos nuevos permite evaluar si el rendimiento del modelo disminuye en perfiles específicos.
Realización de auditorías periódicas
Las auditorías regulares son un complemento esencial al seguimiento continuo. Una auditoría algorítmica revisa sistemáticamente todas las etapas del modelo para identificar posibles decisiones sesgadas en su funcionamiento. Esto incluye análisis de fallos, pruebas específicas para detectar sesgos demográficos y pruebas adversariales diseñadas para desafiar al sistema.
Según Clementina Stenvers, del Comité Editorial de MD&CO Consulting Group: "La auditoría algorítmica médica es una herramienta que se puede utilizar para comprender mejor las debilidades de un sistema de inteligencia artificial y establecer mecanismos para mitigar su impacto".
Un protocolo de auditoría eficaz requiere la colaboración de equipos multidisciplinares que incluyan profesionales sanitarios, científicos de datos y expertos en ética. Estos equipos pueden establecer mecanismos estandarizados para que el personal clínico informe sobre anomalías o resultados inesperados que puedan indicar nuevos sesgos. Además, mantener registros claros de las fuentes de datos, criterios de decisión y estrategias de mitigación facilita la validación externa y refuerza la responsabilidad ética.
Por último, aplicar principios de Análisis de Modos de Fallo y Efectos (FMEA) permite priorizar y abordar riesgos algorítmicos de manera estructurada. Este enfoque ayuda a identificar eventos críticos que deben evitarse y orienta las auditorías hacia áreas que impactan directamente en la seguridad del paciente. Estas medidas integradas son clave para mantener la equidad y la fiabilidad del modelo en entornos clínicos.
Métricas y herramientas para la validación ética
Métricas clave para detectar sesgos
Seleccionar las métricas correctas es clave para evaluar si un algoritmo médico funciona de manera justa para todos los pacientes. Por ejemplo, la sensibilidad mide cuántos casos enfermos son identificados correctamente. En el contexto del cribado de cáncer, una sensibilidad baja puede ser peligrosa, ya que genera falsos negativos, dejando sin diagnosticar casos importantes. Por otro lado, la especificidad mide la capacidad de identificar correctamente a personas sanas. Una baja especificidad puede causar falsos positivos, lo que genera ansiedad innecesaria y costes adicionales.
El umbral diagnóstico juega un papel crucial en equilibrar sensibilidad y especificidad.
Según el Dr. Josep Malvehy Guilera, Director de la Unidad de Cáncer de Piel del Hospital Clínic de Barcelona: "Si comete un error diagnosticando melanoma en lesiones con riesgo potencial de crecer rápidamente... tengo que ser muy intolerante. Tengo que pedir sensibilidades del 92, 93, 94% como mínimo".
Un caso relevante es el del algoritmo Quantus Skin, que alcanzó una sensibilidad del 69,1% y una especificidad del 80,2%. Esto significa que no detectó casi uno de cada tres melanomas.
La Dra. Rosa Taberner Ferrer, dermatóloga del Hospital Son Llàtzer, lo explica de manera contundente: "Una tasa del 31% de falsos negativos suena peligrosa como mínimo. Como herramienta de cribado, es un fracaso".
Además, el análisis desagregado por grupos demográficos (como edad, género o etnia) ayuda a identificar diferencias de rendimiento específicas. Un dato preocupante muestra que solo el 12% de los estudios de IA médica evalúan la presencia de sesgos, siendo el racial el más común, seguido por el de género y edad.
Incorporación de validación en plataformas sanitarias
Definir métricas éticas es solo el primer paso; integrarlas en las plataformas sanitarias es igual de importante para garantizar resultados justos. Las herramientas de análisis pueden incluir sistemas para detectar sesgos directamente en sus procesos.
Fairness Indicators de TensorFlow, por ejemplo, evalúa métricas de equidad en clasificadores. Compara el rendimiento del modelo entre diferentes subgrupos utilizando intervalos de confianza para identificar discrepancias significativas. Además, puede integrarse fácilmente en flujos de trabajo estándar mediante componentes como TFX Evaluator o plugins de TensorBoard.
Por su parte, TensorFlow Model Remediation ofrece soluciones para reducir sesgos durante el entrenamiento. Herramientas como MinDiff equilibran las tasas de error entre diferentes segmentos de datos (por ejemplo, entre pacientes masculinos y femeninos). Otra técnica, Counterfactual Logit Pairing (CLP), asegura que cambiar un atributo sensible, como el género, no altere la predicción del modelo.
Otra herramienta destacada es Amazon SageMaker Clarify, que incluye métricas como la Diferencia de Rechazo Condicional (DCR). Esta métrica mide sesgos comparando las etiquetas reales de los datos de entrenamiento con las predicciones del modelo en distintos grupos demográficos.
Estas herramientas son especialmente útiles en plataformas como Mundoctor, donde garantizar la equidad en la asignación de citas médicas es crucial. Implementar revisiones periódicas y contar con equipos interdisciplinares que incluyan sanitarios, expertos en ética y científicos de datos permite mantener una validación constante de los resultados.
Conclusión: Buenas prácticas para algoritmos médicos libres de sesgos
Detectar y corregir los sesgos en los algoritmos médicos no es solo una cuestión técnica, sino una responsabilidad ética que afecta directamente la calidad del sistema sanitario. Por ello, es crucial adoptar un enfoque global que abarque desde la recolección inicial de datos hasta el seguimiento continuo tras la implementación.
Como menciona el Dr. Enrique Angarita de iamedica.org: "La equidad algorítmica no es una opción técnica, es un imperativo moral".
Incluir datos que reflejen la diversidad en términos de edad, género, etnia y nivel socioeconómico es clave para evitar que se excluyan o invisibilicen ciertos grupos. Además, es fundamental evitar el uso de variables proxy sesgadas, como medir la necesidad médica basándose en el coste sanitario previo, ya que estas prácticas pueden perpetuar desigualdades existentes.
Realizar auditorías periódicas tras la implementación del algoritmo permite evaluar su rendimiento a lo largo del tiempo y analizar cómo afecta a diferentes subgrupos demográficos. Estas revisiones aseguran que las medidas tomadas en las primeras fases del desarrollo se mantengan en el uso diario.
La colaboración entre disciplinas es otro pilar fundamental. Los equipos deben incluir médicos, especialistas en datos, expertos en ética y representantes de las comunidades afectadas. De igual forma, la transparencia en el diseño y la documentación detallada de los datos, los criterios de decisión y el funcionamiento del modelo son esenciales para garantizar la rendición de cuentas y facilitar la validación externa.
Por ejemplo, plataformas como Mundoctor pueden adoptar estas prácticas para asegurar que procesos como la asignación de citas médicas sean justos y equitativos, beneficiando por igual a todos los pacientes. Estas medidas no solo mejoran la confianza en los sistemas automatizados, sino que también refuerzan su impacto positivo en la atención médica.
FAQs
¿Qué datos mínimos necesito para detectar sesgos por edad, género o etnia?
Para identificar posibles sesgos relacionados con la edad, el género o la etnia en un sistema, es necesario recopilar datos demográficos básicos del paciente, como su edad, género y origen étnico. Además, resulta crucial disponer de los resultados clínicos o las predicciones generadas por el algoritmo. Esto permite analizar si existen diferencias sistemáticas que estén vinculadas a estas características demográficas.
¿Cómo sé si una “variable proxy” está discriminando sin que me dé cuenta?
Para determinar si una variable proxy está generando discriminación, es fundamental analizar cómo funciona el algoritmo en diferentes subgrupos poblacionales. Esto implica evaluar su desempeño de manera segmentada y comparar los resultados. Además, es crucial realizar un seguimiento periódico de los resultados para identificar posibles sesgos sistemáticos o desigualdades, ya sea en diagnósticos o tratamientos. Los sesgos en los algoritmos suelen ser un reflejo de prejuicios presentes en los datos de entrenamiento, lo que, si no se aborda, puede contribuir a mantener o incluso agravar las desigualdades en el ámbito de la salud.
¿Cada cuánto debo auditar el algoritmo tras ponerlo en producción?
Realizar auditorías regulares a los algoritmos es clave para detectar posibles sesgos y asegurar que operen de manera justa y eficiente. La periodicidad de estas revisiones puede variar según el contexto y las necesidades específicas del sistema en cuestión. Adaptar esta frecuencia a los cambios y exigencias del entorno ayudará a mantener la calidad y confiabilidad del algoritmo.